You know what zombies are, right? No matter how often you kill them, they just keep coming back. So it is with zombie statistics. No matter how often they are debunked, people will keep repeating them as if they were a fact.

Picture credit: Scott Beale / Laughing Squid
As all fans of a particular horror movie genre know, the only way you can kill a zombie is to shoot it in the head. This blog post is my attempt at a headshot for the zombie statistic “only half of all clinical trials have ever been published”.
That statistic has been enthusiastically promoted by the All Trials campaign. The campaign itself is fighting for a thoroughly good cause. Their aim is to ensure that the results of all clinical trials are disclosed in the public domain. Seriously, who wouldn’t want to see that happen? Medical science, or indeed any science, can only progress if we know what previous research has shown.
But sadly, All Trials are not being very evidence-based in their use of statistics. They have recently written yet another article promoting the “only half of all clinical trials are published” zombie statistic, which I’m afraid is misleading in a number of ways.
The article begins: “We’re sometimes asked if it’s still true that around half of clinical trials have never reported results. Yes, it is.” Or at least that’s how it starts today. The article has been silently edited since it first appeared, with no explanation of why. That’s a bit odd for an organisation that claims to be dedicated to transparency.
The article continues “Some people point towards recent studies that found a higher rate of publication than that.” Well, yes. There are indeed many studies showing much higher rates of publication for recent trials, and I’ll show you some of those studies shortly. It’s good that All Trials acknowledge the recent increase in publication rates.
“But these studies look at clinical trials conducted very recently, often on the newest drugs, and therefore represent a tiny fraction of all the clinical trials that have ever been conducted”, the All Trials campaign would have us believe.
It’s worth looking at that claim in some detail.
Actually, the studies showing higher rates of publication are not necessary conducted very recently. It’s true that some of the highest rates come from the most recent studies, as there has been a general trend to greater disclosure for some time, which still seems to be continuing. But rates have been increasing for a while now (certainly since long before the All Trials campaign was even thought of, in case you are tempted to believe the spin that recent increases in disclosure rates are a direct result of the campaign), so it would be wrong to think that rates of publication substantially higher than 50% have only been seen in the last couple of years. For example, Bourgeois et al’s 2010 study, which found 80% of trials were disclosed in the public domain, included mostly trials conducted over 10 years ago.
It’s a big mistake to think that trials in the last 10 years have a negligible effect on the totality of trials. The number of clinical trials being done has increased massively over time, so more recent trials are actually quite a large proportion of all trials that have ever been done. And certainly a large proportion of all trials that are still relevant. How much do you think this 1965 clinical trial of carbenoxolone sodium is going to inform treatment of gastric ulcers today in the era of proton pump inhibitors, for example?
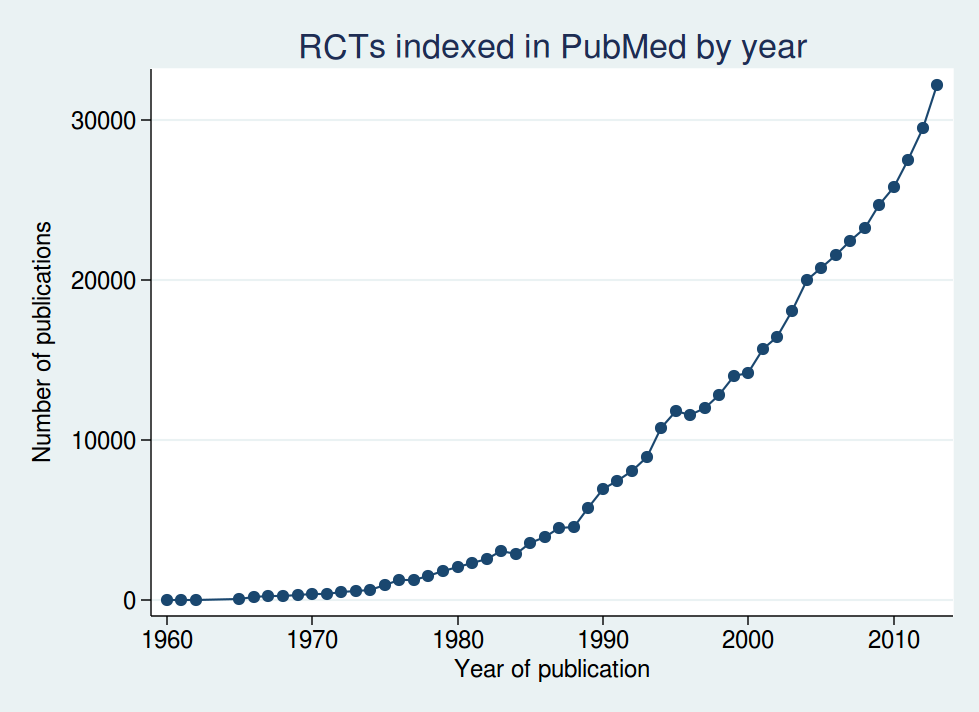
If we look at the number of randomised controlled trials indexed in PubMed over time, we see a massive increase over the last couple of decades:
In fact over half of all those trials have been published since 2005. I wouldn’t say over half is a “tiny fraction”, would you?
“Ah”, I hear you cry, “but what if more recent trials are more likely to be published? Maybe it only looks like more trials have been done recently.”
Yes, fair point. It is true that in the last century, a significant proportion of trials were unpublished. Maybe it was even about half, although it’s hard to know for sure, as there is no good estimate of the overall proportion, despite what All Trials would have you believe (and we’ll look at their claims in more detail shortly).
But even if we make the rather extreme assumption that up to 2000 only half of all trials were published, then the rate increased evenly up to 2005 from which point 100% of trials were published, then the date after which half of all trials were done only shifts back as far as 2001.
So the contribution of recent trials matters. In fact even the All Trials team themselves tacitly acknowledge this, if you look at the last sentence of their article:
“Only when all of this recent research is gathered together with all other relevant research and assessed in another systematic review will we know if this new data changes the estimate that around half of clinical trials have ever reported results.”
In other words, at the moment, we don’t know whether it’s still true that only around half of clinical trials have ever reported results. So why did they start by boldly stating that it is true?
The fact is that no study has ever estimated the overall proportion of trials that have been published. All Trials claim that their figure of 50% comes from a 2010 meta-analysis by Song et al. This is a strange claim, as Song et al do not report a figure for the proportion of trials published. Go on. Read their article. See if you can find anything saying “only 50% of trials are published”. I couldn’t. So it’s bizarre that All Trials claim that this paper is the primary support for their claim.
The paper does, however, report publication rates in several studies of completeness of publication, and although no attempt is made to combine them into an overall estimate, some of the figures are in the rough ballpark of 50%. Maybe All Trials considered that close enough to support a nice soundbite.
But the important thing to remember about the Song et al study is that although it was published in 2010, it is based on much older data. Most of the trials it looks at were from the 1990s, and many were from the 1980s. The most recent study included in the review only included trials done up to 2003. I think we can all agree that publication rates in the last century were way too low, but what has happened since then?
Recent evidence
Several recent studies have looked at completeness of publication, and have shown disclosure rates far higher than 50%.
One important thing to remember is that researchers today have the option of posting their results on websites such as clinicaltrials.gov, which were not available to researchers in the 1990s. So publication in peer reviewed journals is not the only way for clinical trial results to get into the public domain. Any analysis that ignores results postings on websites is going to greatly underestimate real disclosure rates. Some trials are posted on websites and not published in journals, while others are published in journals but not posted on websites. To look at the total proportion of trials with results disclosed in the public domain, you have to look at both.
There may be a perception among some that posting results on a website is somehow “second best”, and only publication in a peer-reviewed journal really counts as disclosure. However, the evidence says otherwise. Riveros et al published an interesting study in 2013, in which they looked at completeness of reporting in journal publications and on clinicaltrials.gov. They found that postings on clinicaltrials.gov were generally more complete than journal articles, particularly in the extent to which they reported adverse events. So perhaps it might even be reasonable to consider journal articles second best.
But nonetheless, I think we can reasonably consider a trial to be disclosed in the public domain whether it is published in a journal or posted on a website.
So what do the recent studies show?
Bourgeois et al (2010) looked at disclosure for 546 trials that had been registered on clinicaltrials.gov. They found that 80% of them had been disclosed (66% in journals, and a further 14% on websites). The results varied according to the funder: industry-sponsored trials were disclosed 88% of the time, and government funded trials 55% of the time, with other trials somewhere in between.
Ross et al (2012) studied 635 trials that had been funded by the NIH, and found 68% had been published in journals. They didn’t look at results posting on websites, so the real disclosure rate may have been higher than that. And bear in mind that government funded trials were the least likely to be published in Bourgeois et al’s study, so Ross et al’s results are probably an underestimate of the overall proportion of studies that were being disclosed in the period they studied.
Rawal and Deane published 2 studies, one in 2014 and one in 2015. Their 2014 study included 807 trials, of which 89% were disclosed, and their 2015 study included 340 trials, of which 92% were disclosed. However, both studies included only trials done by the pharmaceutical industry, which had the highest rates of disclosure in Bourgeois et al’s study, so we can’t necessarily assume that trials from non-industry sponsors are being disclosed at such a high rate.
Taken together, these trials show that the claim that only 50% of trials are published is really not tenable for trials done in the last decade or so. And remember that trials done in the last decade or so make up about half the trials that have ever been done.
Flaws in All Trials’s evidence
But perhaps you’re still not convinced? After all, All Trials include on their page a long list of quite recent references, which they say support their claim that only half of all trials are unpublished.
Well, just having a long list of references doesn’t necessarily mean that you are right. If it did, then we would have to conclude that homeopathy is an effective treatment, as this page from the Society of Homeopaths has an even longer reference list. The important thing is whether the papers cited actually back up your claim.
So let’s take a look at the papers that All Trials cite. I’m afraid this section is a bit long and technical, which is unavoidable if we want to look at the papers in enough detail to properly assess the claims being made. Feel free to skip to the conclusions of this post if long and technical looks at the evidence aren’t your bag.
We’ve already looked at All Trials’s primary reference, the Song et al systematic review. This does show low rates of publication for trials in the last century, but what do the more recent studies show?
Ross et al, 2009, which found that 46% of trials on ClinicalTrials.gov, the world’s largest clinical trials register, had reported results.
For a start, this trial is now rather old, and only included trials up to 2005, so it doesn’t tell us about what’s been happening in the last decade. It is also likely to be a serious underestimate of the publication rate even then, for 3 reasons. First, the literature search for publication only used Medline. Many journals are not indexed in Medline, so just because a study can’t be found with a Medline search does not mean it’s not been published. Pretty much the first thing you learn at medical literature searching school is that searching Medline alone is not sufficient if you want to be systematic, and it is important to search other databases such as Embase as well. Second, and perhaps most importantly, it only considers publications in journals, and does not look at results postings on websites. Third, although they only considered completed trials, 46% of the trials they studied did not report an end date, so it is quite possible that those trials had finished only recently and were still being written up for publication.
Prayle et al, 2012, which found 22% of clinical trials had reported summary results on ClinicalTrials.gov within one year of the trial’s completion, despite this being a legal requirement of the US’s Food and Drug Administration Amendments Act 2007.
This was a study purely of results postings, so tells us nothing about the proportion of trials published in journals. Also, the FDA have criticised the methods of the study on several grounds.
Jones et al, 2013, which found 71% of large randomised clinical trials (those with 500 participants or more) registered on ClinicalTrials.gov had published results. The missing 29% of trials had approximately 250,000 trial participants.
71% is substantially higher than 50%, so it seems odd to use this as evidence to support the 50% figure. Also, 71% is only those trials published in peer-reviewed journals. The figure is 77% if you include results postings on websites. Plus the study sample included some active trials and some terminated trials, so is likely to be an underestimate for completed trials.
Schmucker et al, 2014, which found that 53% of clinical trials are published in journals. This study analysed 39 previous studies representing more than 20,000 trials.
This is quite a complex study. It was a meta-analysis, divided into 2 parts: cohorts of studies approved by ethics committees, and cohorts of studies registered in trial registries. The first part included predominantly old trials from the 1980s and 1990s.
The second part included more recent trials, but things start to unravel if you look at some of the studies more carefully. The first problem is that they only count publications in journals, and do not look at results postings on websites. Where the studies reported both publications and results postings, only the publications were considered, and results postings were ignored.
As with any meta-analysis, the results are only as good as the individual trials. I didn’t look in detail at all the trials included, but I did look at some of the ones with surprisingly low rates of disclosure. The largest study was Huser et al 2013, which found only a 28% rate of disclosure. But this is very misleading. It was only the percentage of trials that had a link to a publication in the clinicaltrials.gov record. Although sponsors should come back and update the clinicaltrials.gov record when they have published the results in a journal to provide a link to the article, in practice many don’t. So only to look at records with such a link is going to be a massive underestimate of the true publication rate (and that’s before we remember that results postings on the clinicaltrials.gov website weren’t counted). It is likely that manually searching for the articles would have found many more trials published.
Another study with a low publication rate included in the meta-analysis was Gopal et al 2012. The headline publication rate was 30%, out of a sample size of of 818. However, all 818 of those had had results posted on clinicaltrials.gov, so in fact the total disclosure rate was 100%, although of course that is meaningless as that was determined by their study design rather than a finding of the study.
The other study with a surprisingly low proportion of disclosed trials was Shamilyan et al 2012, which found only a 23% publication rate. This was only a small study (N=112), but apart from that the main flaw was that it only searched Medline, and used what sounds like a rather optimistic search strategy, using titles and ID numbers, with no manual search. So as far as I can tell from this, if a paper is published without indexing the clinicaltrials.gov ID number (and unfortunately many papers don’t) and didn’t use exactly the same verbatim title for the publication as the clinicaltrials.gov record, then publications wouldn’t have been found.
I haven’t checked all the papers, but if these 3 are anything to go by, there are some serious methodological problems behind Schumcker et al’s results.
Munch et al, 2014, which found 46% of all trials on treatments for pain had published results.
This was a study of 391 trials, of which only 181 had published results, which is indeed 46%. But those 391 trials included some trials that were still ongoing. I don’t think it’s reasonable to expect that a trial should be published before it is completed, do you? If you use the 270 completed trials as the denominator, then the publication rate increases to 67%. And even then, there was no minimum follow-up time specified in the paper. It is possible that some of those trials had only completed shortly before Munch et al searched for the results and were still being written up. It is simply not possible to complete a clinical study one day and publish the results the next day.
Anderson et al, 2015, which found that 13% of 13,000 clinical trials conducted between January 2008 and August 2012 had reported results within 12 months of the end of the trial. By 5 years after the end of the trial, approximately 80% of industry-funded trials and between 42% and 45% of trials funded by government or academic institutions had reported results.
I wonder if they have given the right reference here, as I can’t match up the numbers for 5 years after the end of the trial to anything in the paper. But the Anderson et al 2015 study that they cite did not look at publication rates, only at postings on clinicaltrials.gov. It tells us absolutely nothing about total disclosure rates.
Chang et al, 2015, which found that 49% of clinical trials for high-risk medical devices in heart disease were published in a journal.
The flaws in this study are very similar to those in Ross et al 2009: the literature search only used Medline, and results posting on websites was ignored.
Conclusions
When you look at the evidence in detail, it is clear that the claim that half of all clinical trials are unpublished is not supported. The impression one gets from reading the All Trials blog post is that they have decided that “half of all trials are unpublished” is a great soundbite, and then they try desperately to find evidence that looks like it might back it up if it is spun in a certain way and limitations in the research are ignored. And of course research showing higher rates of disclosure is also ignored.
This is not how to do science. You do not start with an answer and then try to look for a justification for it, while ignoring all disconfirming evidence. You start with a question and then look for the answer in as unbiased a way as possible.
It is disappointing to see an organisation nominally dedicated to accuracy in the scientific literature misusing statistics in this way.
And it is all so unnecessary. There are many claims that All Trials could make in support of their cause without having to torture the data like this. They could (and indeed do) point out that the historic low rate of reporting is still a problem, as many of the trials done in the last century are still relevant to today’s practice, and so it would be great if they could be retrospectively disclosed. If that was where their argument stopped, I would have no problem with it, but to claim that those historic low rates of reporting apply to the totality of clinical trials today is simply not supported by evidence.
All Trials could also point out that the rates of disclosure today are less than 100%, which is not good enough. That would also be a statement no reasonable person could argue with. They could even highlight the difficulty in finding research: many of the studies above do not show low rates of reporting, but they do show that reports of clinical trials can be hard to find. That is definitely a problem, and if All Trials want to suggest a way to fix it, that would be a thoroughly good thing.
There is no doubt that All Trials is fighting for a worthy cause. We should not be satisfied until 100% of clinical trials are disclosed, and we are not there yet. But to claim we are still in a position where only half of clinical trials are disclosed, despite all the evidence that rates of disclosure today are more typically in the region of 80-90%, is nothing short of dishonest.
I don’t care how good your cause is, there is never an excuse for using dodgy statistics as part of your campaigning.