It has probably not escaped your attention that the Department of Health published new guidelines for alcohol consumption on Friday. These guidelines recommend lower limits than the previous guidelines, namely no more than 14 units per week. The figure is the same for men and women.
There are many odd things about these guidelines. But before I get into that, I was rightly picked up on a previous blogpost for not being clear about my own competing interests, so I’ll get those out of the way first, as I think it’s important.
I do not work either for the alcohol industry or in public health, so professionally speaking, I have no dog in this fight. However, at a personal level, I do like a glass of wine or two with my dinner, which I have pretty much every day. So my own drinking habits fall within the recommended limits of the previous guidelines (no more than 4 units per day for men), but under the new guidelines I would be classified as an excessive drinker. Do bear that in mind when reading this blogpost. I have tried to be as impartial as possible, but we are of course all subject to biases in the way we assess evidence, and I cannot claim that my assessment is completely unaffected by being classified as a heavy drinker under the new guidelines.
So, how were the new guidelines developed? This was a mixture of empirical evidence, mathematical modelling, and the judgement of the guidelines group. They were reasonably explicit about this process, and admit that the guidelines are “both pragmatic and evidence based”, so they get good marks for being transparent about their overall thinking.
However, it was not always easy to figure out what evidence was used, so they get considerably less good marks for being transparent about the precise evidence that led to the guidelines. It’s mostly available if you look hard enough, but the opacity of the referencing is disappointing. Very few statements in the guidelines document are explicitly referenced. But as far as I can tell, most of the evidence comes from two other documents, “A summary of the evidence of the health and social impacts of alcohol consumption” (see the document “Appendix 3 CMO Alcohol Guidelines Summary of evidence.pdf” within the zip file that you can download here) ,and the report of the Sheffield modelling group.
The specific way in which “14 units per week” was derived was as follows. The guidelines team investigated what level of alcohol consumption would be associated with no more than an “acceptable risk”, which is fair enough. Two definitions of “acceptable risk” were used, based on recent work in developing alcohol guidelines in Canada and Australia. The Canadian definition of acceptable risk was a relative risk of alcohol-related mortality of 1, in other words, the point at which the overall risk associated with drinking, taking account of both beneficial and harmful effects, was the same as the risk for a non-drinker. The Australian definition of acceptable risk was that the proportion of deaths in the population attributable to alcohol, assuming that everyone in the population drinks at the recommended limit, is 1%. In practice, both methods gave similar results, so choosing between them is not important.
To calculate the the levels of alcohol that would correspond to those risks, a mathematical model was used which incorporated empirical data on 43 diseases which are known to be associated with alcohol consumption. Risks for each were considered, and the total mortality attributable to alcohol was calculated from those risks (although the precise mathematical calculations used were not described in sufficient detail for my liking).
These results are summarised in the following table (table 1 in both the guidelines document and the Sheffield report). Results are presented separately for men and women, and also separately depending on how many days each week are drinking days. The more drinking days you have per week for the same weekly total, the less you have on any given day. So weekly limits are higher if you drink 7 days per week than if you drink 1 day per week, because of the harm involved with binge drinking if you have your entire weekly allowance on just one day.
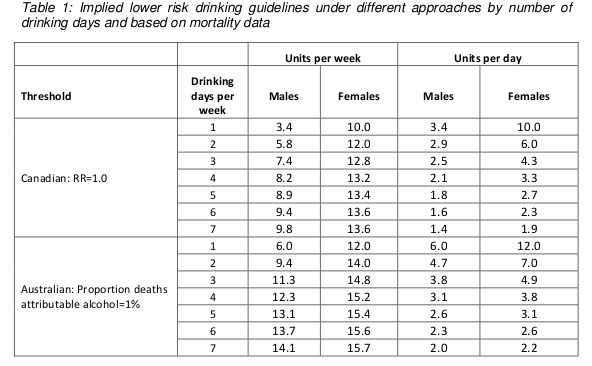
Assuming that drinking is spread out over a few days a week, these figures are roughly in the region of 14, so that is where the guideline figure comes from. The same figure is now being used for men and women.
Something you may have noticed about the table above is that it implies the safe drinking limits are lower for men than for women. You may think that’s a bit odd. I think that’s a bit odd too.
Nonetheless, the rationale is explained in the report. We are told (see paragraph 46 of the guidelines document) that the risks of immediate harm from alcohol consumption, usually associated with binge-drinking in a single session, “are greater for men than for women, in part because of men’s underlying risk taking behaviours”. That sounds reasonably plausible, although no supporting evidence is offered for the statement.
To be honest, I find this result surprising. According to table 6 on page 35 of the Sheffield modelling report, deaths from the chronic effects of alcohol (eg cancer) are about twice as common as deaths from the acute affects of alcohol (eg getting drunk and falling under a bus). We also know that women are more susceptible than men to the longer term effect of alcohol. And yet it appears that the acute effects dominate this analysis.
Unfortunately, although the Sheffield report is reasonably good at explaining the inputs to the mathematical model, specific details of how the model works are not presented. So it is impossible to know why the results come out in this surprising way and whether it is reasonable.
There are some other problems with the model.
I think the most important one is that the relationship between alcohol consumption and risk was often assumed to be linear. This strikes me as a really bad assumption, perhaps best illustrated with the following graph (figure 11 on page 45 of the Sheffield report).
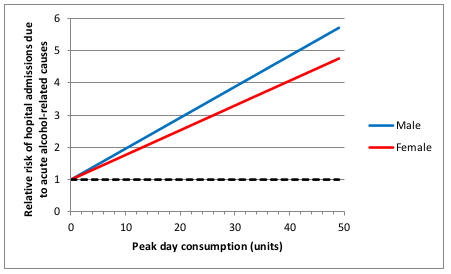
This shows how the risk of hospital admission for acute alcohol-related causes increases as a function of peak day consumption, ie the amount of alcohol drunk in a single day.
A few moments’ thought suggest that this is not remotely realistic.
The risk is expressed as a relative risk, in other words how many times more likely you are to be admitted to hospital for an alcohol-related cause than you are on a day when you drink no alcohol at all. Presumably they consider that there is a non-zero risk when you don’t drink at all, or a relative risk would make no sense. Perhaps that might be something like being injured in a road traffic crash where you were perfectly sober but the other driver was drunk.
But it’s probably safe to say that the risk of being hospitalised for an alcohol-related cause when you have not consumed any alcohol is low. The report does not make it clear what baseline risk they are using, but let’s assume conservatively that the daily risk is 1 in 100, or 1%. That means that you would expect to be admitted to hospital for an alcohol-related cause about 3 times a year if you don’t drink at all. I haven’t been admitted to hospital 3 times in the last year (or even once, in fact) for an alcohol related cause, and I’ve even drunk alcohol on most of those days. I doubt my experience of lack of hospitalisation is unusual. So I think it’s probably safe to assume that 1% is a substantial overestimate of the true baseline risk.
Now let’s look at the top right of the graph. That suggests that my relative risk of being admitted to hospital for an alcohol-related cause would be 6 times higher if I drink 50 units in a day. In other words, that my risk would be 6%. And remember that that is probably a massive overestimate.
Now, 50 units of alcohol is roughly equivalent to a bottle and a half of vodka. I don’t know about you, but I’m pretty sure that if I drank a bottle and a half of vodka in a single session then my chances of being hospitalised – if I survived that long – would be close to 100%.
So I don’t think that a linear function is realistic. I don’t have any data on the actual risk, but I would expect it to look something more like this:
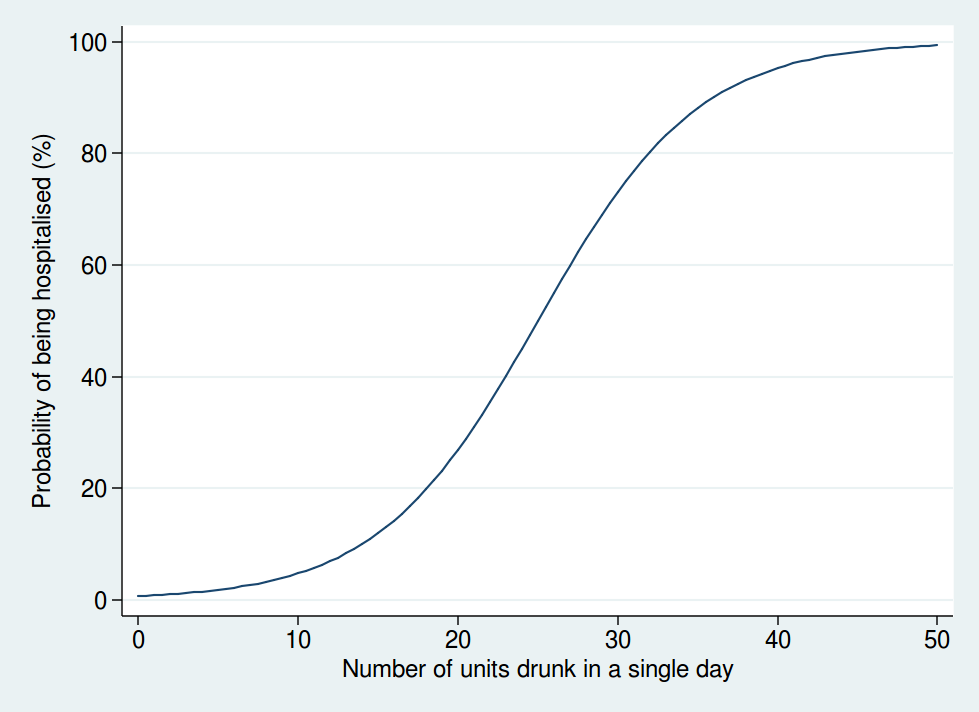
Here we see that the risk is negligible at low levels of alcohol consumption, then increases rapidly once you get into the range of serious binge drinking, and approaches 100% as you consume amounts of alcohol unlikely to be compatible with life. The precise form of that graph is something I have just guessed at, but I’m pretty sure it’s a more reasonable guess than a linear function.
A mathematical model is only as good as the data used as inputs to the model and the assumptions used in the modelling. Although the data used are reasonably clearly described and come mostly from systematic reviews of the literature, the way in which the data are modelled is not sufficiently clear, and also makes some highly questionable assumptions. Although some rudimentary sensitivity analyses were done, no sensitivity analyses were done using risk functions other than linear ones.
So I am not at all sure I consider the results of the mathematical modelling trustworthy. Especially when it comes up with the counter-intuitive result that women can safely drink more than men, which contradicts most of the empirical research in this area.
But perhaps more importantly, I am also puzzled why it was felt necessary to go through a complex modelling process in the first place.
It seems to me that the important question here is how does your risk of premature death depend on your alcohol consumption. That, at any rate, is what was modelled.
But there is no need to model it: we actually have empirical data. A systematic review of 34 prospective studies by Di Castelnuovo et al published in 2006 looked at the relationship between alcohol consumption and mortality. This is what it found (the lines on either side of the male and female lines are 99% confidence intervals).
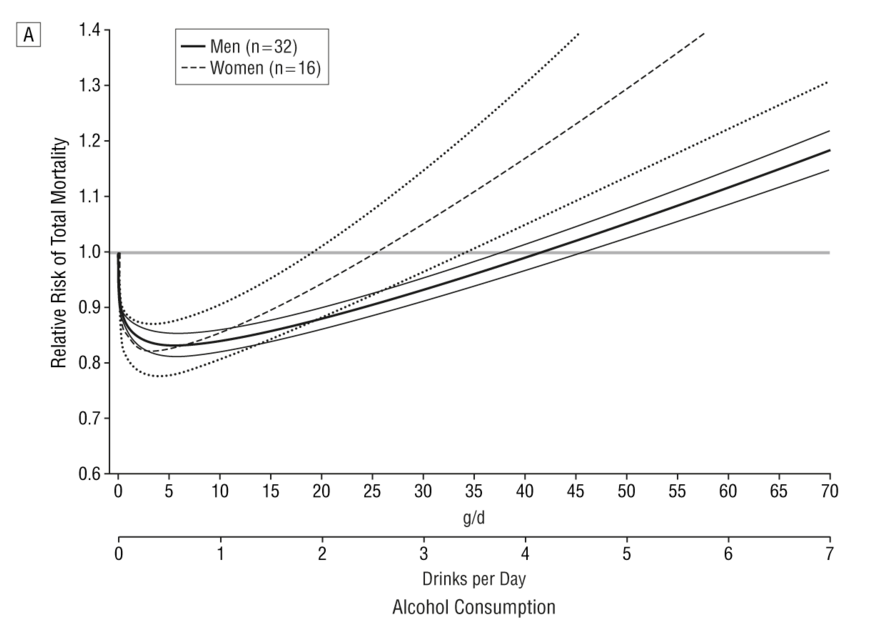
This shows that the level of alcohol consumption associated with no increased mortality risk compared with non-drinkers is about 25 g/day for women and 40 g/day for men. A standard UK unit is 8 g of alcohol, so that converts to about 22 units per week for women and 35 units per week for men: not entirely dissimilar to the previous guidelines.
Some attempt is made to explain why the data on all cause mortality have not been used, but I do not find them convincing (see page 7 of the summary of evidence).
One problem we are told is that “most of the physiological mechanisms that have been suggested to explain the protective effect of moderate drinking only apply for cohorts with overall low levels of consumption and patterns of regular drinking that do not vary”. That seems a bizarre criticism. The data show that there is a protective effect only at relatively low levels of consumption, and that once consumption increases, so does the risk. So of course the protective effect only applies at low levels of consumption. As for the “patterns of regular drinking”, the summary makes the point that binge drinking is harmful. Well, we know that. The guidelines already warn of the dangers of binge drinking. It seems odd therefore, to also reject the findings for people who split their weekly consumption evenly over the week and avoid binge drinking, as this is exactly what the guidelines say you should do.
I do not understand why studies which apply to people who follow safe drinking guidelines are deemed to be unsuitable for informing safe drinking guidelines. That makes no sense to me.
The summary also mentions the “sick quitter hypothesis” as a reason to mistrust the epidemiological data. The sick quitter hypothesis suggests that the benefits of moderate drinking compared with no drinking may have been overestimated in epidemiological studies, as non-drinkers may include recovering alcoholics and other people who have given up alcohol for health reasons, and therefore include an unusually unhealthy population.
The hypothesis seems reasonable, but it is not exactly a new revelation to epidemiologists, and has been thoroughly investigated. The systematic review by Di Castelnuovo reported a sensitivity analysis including only studies which excluded former drinkers from their no-consumption category. That found a lower beneficial effect on mortality than in the main analysis, but the protective effect was still unambiguously present. The point at which drinkers had the same risk as non-drinkers in that analysis was about 26 units per week (this is an overall figure: separate figures for men and women were not presented in the sensitivity analysis).
A systematic review specifically of cardiovascular mortality by Ronksley et al published in 2011 also ran a sensitivity analysis where only lifelong non-drinkers were used as the reference category, and found it made little difference to the results.
So although the “sick quitter hypothesis” sounds like a legitimate concern, in fact it has been investigated and is not a reason to distrust the results of the epidemiological analyses.
So all in all, I really do not follow the logic of embarking on a complex modelling exercise instead of using readily available empirical data. Granted, the systematic review by Di Castelnuovo et al is 10 years old now, but surely a more appropriate response to that would have been to commission an updated systematic review rather than ignore the systematic review evidence on mortality altogether and go down a different and problematic route.
Does any of this matter? After all, the guidelines are not compulsory. If my own reading of the evidence tells me I can quite safely drink 2 glasses of wine with my dinner most nights, I am completely free to do so.
Well, I think this does matter. If the government are going to publish guidelines on healthy behaviours, I think it is important that they be as accurate and evidence-based as possible. Otherwise the whole system of public health guidelines will fall into disrepute, and then it is far less likely that even sensible guidelines will be followed.
What is particularly concerning here is the confused messages the guidelines give about whether moderate drinking has benefits. From my reading of the literature, it certainly seems likely that there is a health benefit at low levels of consumption. That, at any rate, is the obvious conclusion from Di Castelnuovo et al’s systematic review.
And yet the guidelines are very unclear about this. While even the Sheffield model used to support the guidelines shows decreased risks at low levels of alcohol consumption (and those decreased risks would extend to substantially higher drinking levels if you base your judgement on the systematic review evidence), the guidelines themselves say that such decreased risks do not exist.
The guideline itself says “The risk of developing a range of diseases (including, for example, cancers of the mouth, throat, and breast) increases with any amount you drink on a regular basis”. That is true, but it ignore the fact that it is not true for other diseases. To mention only the harms of alcohol and ignore the benefits in the guidelines seems a dishonest way to present data. Surely the net effect is what is important.
Paragraph 30 of the guidelines document says “there is no level of drinking that can be recommended as completely safe long term”, which is also an odd thing to say when moderate levels of drinking have a lower risk than not drinking at all.
There is no doubt that the evidence on alcohol and health outcomes is complex. For obvious reasons, there have been no long-term randomised controlled trials, so we have to rely on epidemiological research with all its limitations. So I do not pretend for a moment that developing guidelines on what is a safe amount of alcohol to drink is easy.
But despite that, I think the developers of these guidelines could have done better.